What is Graph Matching¶
This page provides some background information for graph matching.
Introduction¶
Graph Matching (GM) is a fundamental yet challenging problem in pattern recognition, data mining, and others. GM aims to find node-to-node correspondence among multiple graphs, by solving an NP-hard combinatorial problem. Recently, there is growing interest in developing deep learning based graph matching methods.
Graph matching techniques have been applied to the following applications:
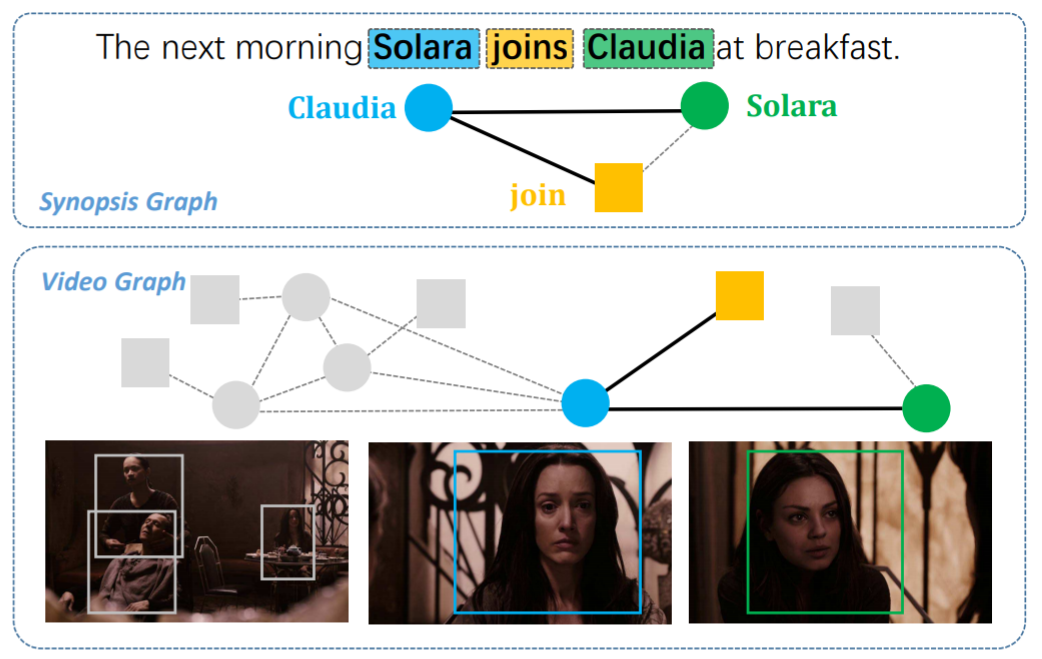

Graph Matching Pipeline¶
Solving a real world graph matching problem may involve the following steps:
Extract node/edge features from the graphs you want to match.
Build affinity matrix from node/edge features.
Solve the graph matching problem by GM solvers.
And Step 1 maybe done by methods depending on your application, Step 2&3 can be handled by pygmtools.
The Math Form¶
Let’s involve a little bit math to better understand the graph matching pipeline. In general, graph matching is of the following form, known as Quadratic Assignment Problem (QAP):
The notations are explained as follows:
\(\mathbf{X}\) is known as the permutation matrix which encodes the matching result. It is also the decision variable in graph matching problem. \(\mathbf{X}_{i,a}=1\) means node \(i\) in graph 1 is matched to node \(a\) in graph 2, and \(\mathbf{X}_{i,a}=0\) means non-matched. Without loss of generality, it is assumed that \(n_1\leq n_2.\) \(\mathbf{X}\) has the following constraints:
The sum of each row must be equal to 1: \(\mathbf{X}\mathbf{1} = \mathbf{1}\);
The sum of each column must be equal to, or smaller than 1: \(\mathbf{X}\mathbf{1} \leq \mathbf{1}\).
\(\mathtt{vec}(\mathbf{X})\) means the column-wise vectorization form of \(\mathbf{X}\).
\(\mathbf{1}\) means a column vector whose elements are all 1s.
\(\mathbf{K}\) is known as the affinity matrix which encodes the information of the input graphs. Both node-wise and edge-wise affinities are encoded in \(\mathbf{K}\):
The diagonal element \(\mathbf{K}_{i + a\times n_1, i + a\times n_1}\) means the node-wise affinity of node \(i\) in graph 1 and node \(a\) in graph 2;
The off-diagonal element \(\mathbf{K}_{i + a\times n_1, j + b\times n_1}\) means the edge-wise affinity of edge \(ij\) in graph 1 and edge \(ab\) in graph 2.
Other Materials¶
Readers are referred to the following surveys for more technical details about graph matching:
Junchi Yan, Shuang Yang, Edwin Hancock. “Learning Graph Matching and Related Combinatorial Optimization Problems.” IJCAI 2020.
Junchi Yan, Xu-Cheng Yin, Weiyao Lin, Cheng Deng, Hongyuan Zha, Xiaokang Yang. “A Short Survey of Recent Advances in Graph Matching.” ICMR 2016.